합의 법칙
두 사건 𝑨와 𝑩가 상호 배타적(동시에 발생할 수 없는 경우)일 때, 사건 𝑨가 일어나는 경우의 수가 m이고,
사건 𝑩가 일어나는 경우의 수가 n이면, 사건 𝑨또는 사건 𝑩가 일어나는 경우의 수의 총합은 m + n
주사위를 한 번 던질 때 짝수가 나오거나 홀수가 나오는 경우의 수
짝수 3가지 + 홀수 3가지 = 6가지
곱의 법칙
두 가지 이상의 사건이 동시에 일어나는 경우의 수
꽃병 3개, 장미 6송이가 있을 때, 꽃병에 장미를 꽃기 위해 꽃병 한 개와 장미 한 송이를 동시에 택하는 경우의 수
3 x 6 = 18
옷장에 셔츠 3벌, 바지 2벌, 신발 2켤레가 있다. 셔츠, 바지, 신발을 하나씩 골라 입을 때, 가능한 옷차림의 경우의 수는?
3 x 2 x 2 = 12가지
순열 (Permutation)
주어진 집합의 원소들을 특정한 순서로 배열하는 방법
예) 집합 {A,B} 가 있을 때 가능한 순열은 AB와 BA
순열에서는 원소의 순서가 매우 중요하며, 순서가 바뀌면 서로 다른 순열로 간주함
예 1) AB 와 BA 는 서로 다른 순열
예 2) 비밀번호 "1234" 와 "4321" 은 서로 다른 비밀번호
전체 순열: 서로 다른 n개의 원소를 가진 집합에서 모든 원소를 사용하여 만들수 있는 순열의 총 개수는 n팩토리얼
n팩토리얼 (1부터 n까지의 자연수를 차례로 곱한 것)
n! = n x (n - 1) x (n - 2) ... 3 x 2 x 1
예) 집합 {A,B,C}가 있을 때 순열의 총 개수는 3 x 2 x 1 = 6
부분 순열:
서로 다른 n개의 원소 중에서 서로 다른 r개를 선택하여 순서를 고려해 배열하는 것
P(n, r) = n x (n - 1) x (n - 2) ... (n - r + 1)
P = Permutation
nPr 이라고도 씀

다른 수식 표현

예) 1, 2, 3, 4와 같은 4장의 숫자카드가 있을 때, 2장을 선택하여 두자리 자연수를 만드는 방법의 수
n = 4, r = 2, n - r + 1 = 3 => 4 x 3 = 12
or
(4 x 3 x 2 x 1) / (2 x 1) => 4 x 3 = 12
import itertools
# 1,2,3,4 숫자가 적힌 카드가 있다
cards = [1,2,3,4]
# 카드 중 두 장 꺼내는 경우
res = list(itertools.permutations(cards, 2))
print(res)
print(len(res))
import math
cards = [1, 2, 3, 4]
n = len(cards)
r = 2
res = math.perm(n, r)
print(res)12
import math
cards = [1,2,3,4]
n = len(cards)
r = 2
res = math.factorial(n) / math.factorial(n - r)
print(res)12.0
조합 (Combination)
주어진 집합에서 순서에 상관없이 일부 원소들을 선택하는 방법
AB, BA 는 동일
순서 중요하지 않음
예) 로또번호뽑기

from itertools import combinations
cards = [1, 2, 3, 4]
b = list(combinations(cards, 2))
print(b)
len(b)
import math
cards = [1, 2, 3, 4]
n = len(cards)
r = 2
res = math.comb(n, r)
print(res)6
import math
cards = [1, 2, 3, 4]
n = len(cards)
r = 2
res = math.factorial(n) / (math.factorial(n - r) * math.factorial(r))
print(res)6
확률 Probability
시행: 동일한 조건에서 반복할 수 있으며, 그 결과가 우연에 의해 결정되는 관찰이나 실험
예) 동전 던지기, 주사위 던지기, 제비뽑기처럼 결과를 예측할 수 없는 행위
표본 공간: 한 시행에서 일어날 수 있는 모든 결과의 집합
예) 주사위를 던지는 시행의 표본 공간은 {1, 2, 3, 4, 5, 6}
근원사건: 표본공간을 구성하는 각각의 개별적인 결과, 즉 실험이나 시행에서 일어날 수 있는 단일한 사건
예) 주사위를 던지는 시행에서 '1이 나오는 것', '2가 나오는 것', ..., '6이 나오는 것' 각각이 근원사건
사건: 표본공간 내의 근원사건들의 집합으로, 특정 실험이나 시행에서 발생할 수 있는 결과들의 부분집합
예) 주사위를 1회 던졌을 때, 홀수가 나올 사건 {1, 3, 5}
합사건: "A 또는 B" 와 같이 여러 사건 중 하나라도 일어나면 만족하는 사건

곱사건: 사건 𝐴와 𝐵에 대해 𝐴와 𝐵가 모두 동시에 발생하는 사건

배반사건: 사건 𝐴와 𝐵에 대해 𝐴와 𝐵가 동시에 발생할 수 없고 하나가 발생하면 다른 하나는 반드시 발생하지 않는 사건

여사건: 어떤 사건이 일어나지 않을 사건을 말합니다. 즉, 전체 경우의 수에서 특정 사건이 일어나는 경우를 제외한 나머지 경우를 의미합니다.

수학적 확률

P(A) = n / N
P(A): 사건 A가 일어날 확률
n: 사건 A에 속하는 경우의 수
N: 모든 가능한 경우의 수 (표본 공간의 크기)
예)
주사위를 던지는 시행에서 짝수가 나오는 사건을 A라고 하면,
P(A): 짝수가 나올 확률
n: 짝수가 나오는 경우의 수 = 3 (2, 4, 6)
N: 모든 가능한 경우의 수 = 6 (1, 2, 3, 4, 5, 6)
따라서, 짝수가 나올 확률 P(A) = 3/6 = 1/2 입니다.
모든 사건 𝐴에 대하여 확률 𝑃(𝐴)는 0 ≤ 𝑃(𝐴) ≤ 1
반드시 발생하는 사건 𝑆에 대하여 확률 𝑃(𝑆) = 1
절대로 발생하지 않는 사건 ∅에 대하여 𝑃(∅) = 0
통계적 확률
실제로 시행을 여러 번 반복하여 얻은 결과를 바탕으로 계산하는 확률
통계적 확률 = (특정 사건이 일어난 횟수) / (전체 시행 횟수)
시행 횟수가 많을수록 통계적 확률은 수학적 확률에 가까워지는 경향이 있습니다. (큰 수의 법칙)

통계적 확률은 시행 횟수를 무한히 늘리면 수학적 확률에 가까워집니다.
하지만 현실에서는 무한히 시행을 반복할 수 없으므로, 통계적 확률은 수학적 확률의 추정치로 볼 수 있습니다.
확률의 덧셈법칙
두 사건 A와 B에 대하여, A 또는 B가 일어날 확률은
P(A ∪ B) = P(A) + P(B) - P(A ∩ B)
P(A ∪ B): 사건 A 또는 사건 B가 일어날 확률 (합사건의 확률)
P(A): 사건 A가 일어날 확률
P(B): 사건 B가 일어날 확률
P(A ∩ B): 사건 A와 사건 B가 동시에 일어날 확률 (교사건의 확률)
배반사건의 경우 P(A ∩ B) = 0 이므로
P(A ∪ B) = P(A) + P(B)
예 1)
1부터 10까지 숫자가 적힌 공 10개가 들어있는 주머니에서 공 1개를 뽑을 때, 2의 배수가 나오는 사건을 A, 5의 배수가 나오는 사건을 B라고 하면, 사건 A 또는 사건 B가 발생할 확률은?
1/2 + 1/5 - 1/10 = 5/10 + 2/10 - 1/10 = 6/10 = 3/5
예 2)
주사위를 던지는 시행에서, 짝수가 나오는 사건을 A, 3의 배수가 나오는 사건을 B라고 하면, 사건 A 또는 사건 B가 발생할 확률은?
P(A ∪ B) = P(A) + P(B) - P(A ∩ B) = 1/2 + 1/3 - 1/6 = 2/3
조건부 확률
어떤 사건 A가 일어났다는 조건 하에 다른 사건 B가 일어날 확률을 말합니다. 즉, 사건 A가 이미 발생한 상황에서 사건 B가 발생할 확률을 계산하는 것입니다.
P(B|A)로 표기하며, "A가 주어졌을 때 B의 확률" 또는 "A 조건 하에서 B의 확률"이라고 읽습니다.
발음) B 기븐 A
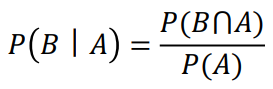
P(B|A): A가 일어났을 때 B가 일어날 확률 (조건부 확률)
P(A ∩ B): A와 B가 동시에 일어날 확률 (교사건의 확률)
P(A): 사건 A가 일어날 확률
예)
카드 한 벌(조커 제외 52장)에서 카드 한 장을 뽑습니다.
뽑은 카드가 하트일 때, 그 카드가 K일 확률은?
사건 A: 뽑은 카드가 하트인 사건
사건 B: 뽑은 카드가 K인 사건
P(A): 카드 52장 중 하트는 13장이므로, P(A) = 13/52 = 1/4 입니다.
P(A ∩ B): 하트이면서 K인 카드는 1장 (하트 K)이므로, P(A ∩ B) = 1/52 입니다.
P(B|A) = P(A ∩ B) / P(A) = (1/52) / (1/4) = 1/13
뽑은 카드가 하트일 때, 그 카드가 K일 확률은 1/13
확률의 곱셈법칙
두 사건이 동시에 또는 순차적으로 일어날 확률을 계산하는 데 사용되는 법칙
1. 두 사건이 동시에 일어날 확률
P(A ∩ B) = P(A) * P(B|A) = P(B) * P(A|B)
P(A ∩ B): 사건 A와 사건 B가 동시에 일어날 확률 (교사건의 확률)
P(A): 사건 A가 일어날 확률
P(B): 사건 B가 일어날 확률
P(B|A): 사건 A가 일어났을 때 사건 B가 일어날 확률 (조건부 확률)
P(A|B): 사건 B가 일어났을 때 사건 A가 일어날 확률 (조건부 확률)
2. 두 사건이 순차적으로 일어날 확률 (곱사건의 확률)
P(A × B) = P(A) * P(B|A)
P(A × B): 사건 A가 일어난 후 사건 B가 일어날 확률 (곱사건의 확률)
P(A): 사건 A가 일어날 확률
P(B|A): 사건 A가 일어났을 때 사건 B가 일어날 확률 (조건부 확률)
특별한 경우: 독립 사건
두 사건 A와 B가 서로 영향을 미치지 않는 경우 (독립 사건)에는 P(B|A) = P(B) 이므로
P(A ∩ B) = P(A) * P(B)
P(A × B) = P(A) * P(B)
예)
동전을 두 번 던져서 모두 앞면이 나올 확률: 1/2 * 1/2 = 1/4
주머니에서 빨간 공을 꺼낸 후 (다시 넣지 않고) 파란 공을 꺼낼 확률: (빨간 공 개수 / 전체 공 개수) * (파란 공 개수 / 남은 공 개수)
종속 사건
한 사건의 발생 여부가 다른 사건의 발생 확률에 영향을 미치는 사건을 말합니다. 즉, 두 사건 A와 B에 대해 사건 A가 일어났는지 여부에 따라 사건 B의 확률이 달라지는 경우, A와 B는 종속 사건입니다.
예시)
- 카드 뽑기: 카드 한 벌에서 카드 한 장을 뽑은 후 다시 넣지 않고 두 번째 카드를 뽑는 경우, 첫 번째 카드가 무엇인지에 따라 두 번째 카드를 뽑을 확률이 달라집니다.
- 비 오는 날과 우산: 비가 오는 날(사건 A)에는 우산을 쓸 확률(사건 B)이 높아집니다. 즉, 사건 A가 사건 B에 영향을 미치므로 두 사건은 종속입니다.
문제 1: 주사위와 동전
주사위 한 개와 동전 한 개를 동시에 던질 때, 주사위에서 짝수가 나오고 동전에서 앞면이 나올 확률은 얼마일까요?
정답) 1/2 * 1/2 = 1/4
문제 2: 카드 뽑기
잘 섞인 카드 한 벌(조커 제외 52장)에서 카드를 두 장 연속해서 뽑습니다. 첫 번째 카드가 다이아몬드이고, 두 번째 카드가 스페이드일 확률은 얼마일까요? (단, 첫 번째 카드는 다시 넣지 않습니다.)
정답) 1/4 * 13/51 = 13/204
문제 3: 불량품 검사
어떤 공장에서 생산되는 제품의 불량률이 5%라고 합니다. 이 공장에서 제품을 3개 연속해서 검사할 때, 3개 모두 불량품일 확률은 얼마일까요?
정답) 1/20 * 1/20 * 1/20 = 1/8000 (0.000125)
변수
변화하는 모든 수
사람의 키, 체중 등
인과관계에 의한 구분
독립변수: 다른 변수에 영향을 주는 변수
종속변수: 영향을 받는 변수, 즉 독립변수에 의하여 변화되는 변수
매개변수: 종속변수에 영향을 주는 독립변수 이외의 변수로서 연구에서 통제되어야 할 변수
속성에 따른 구분
질적변수 (범주형 변수) : 숫자로 표현될 수 없고, 범주나 특성을 나타내는 변수
- 비서열 질적변수: 순서나 서열이 없는 변수 (성별, 혈액형, 좋아하는 색깔)
- 서열 질적변수: 순서나 서열이 있는 변수 (학력 (초졸/중졸/고졸/대졸), 만족도 (매우 불만족/불만족/보통/만족/매우 만족), 선호도 (매우 싫어함/싫어함/보통/좋아함/매우 좋아함), 옷 사이즈 (S/M/L/XL))
양적변수: 수치로 측정되는 변수를 말합니다. 즉, 변수의 값이 숫자로 표현되고, 그 숫자들이 의미를 가지는 변수
- 연속변수 : 어떤 범위 안에서 어떤 값이든 가질 수 있는 변수 (체중, 나이, 키)
- 비연속변수 (이산변수) : 셀 수 있는 값을 가지는 변수 (가족 구성원 수, 불량품 개수, 주사위 눈의 수)
데이터: 연구나 조사의 목적에 맞는 변수를 토대로, 표본으로부터 수집한 자료
1. 단일변수 데이터 (Univariate Data)
하나의 변수로만 구성된 데이터
예) 학생들의 키, 중간고사 점수, 제품의 무게, 설문 조사에서 '만족도'에 대한 응답
2. 다중변수 데이터 (Multivariate Data)
두 개 이상의 변수로 구성된 데이터
예) 학생들의 키와 몸무게, 중간고사 점수와 기말고사 점수, 제품의 무게와 가격, 설문 조사에서 '만족도'와 '재구매 의사'에 대한 응답
척도
1. 범주형 척도
- 데이터를 구분 지어 나눌 수 있는 척도입니다.
- 범주형 척도는 다시 명목 척도와 서열 척도로 구분됩니다.
- 명목 척도:
- 데이터를 단순히 분류하기 위한 척도입니다.
- 범주 간에 순서나 서열이 없습니다.
- 예: 성별 (남/여), 혈액형 (A/B/O/AB), 좋아하는 색깔 (빨강/파랑/노랑)
- 서열 척도:
- 범주 사이에 순서나 서열이 있는 척도입니다.
- 범주 간의 우열이나 크기는 비교할 수 있지만, 그 차이가 일정하거나 측정 가능하지는 않습니다.
- 예: 학력 (초졸/중졸/고졸/대졸), 만족도 (매우 불만족/불만족/보통/만족/매우 만족), 옷 사이즈 (S/M/L/XL)
- 명목 척도:
2. 연속형 척도
- 연속하는 속성의 데이터를 연구나 조사의 목적에 맞게 구분한 척도입니다.
- 연속형 척도는 다시 등간 척도와 비율 척도로 구분됩니다.
- 등간 척도:
- 범주 사이의 간격이 일정한 척도입니다.
- 덧셈과 뺄셈 연산은 가능하지만, 곱셈과 나눗셈 연산은 불가능합니다.
- 예: 온도 (섭씨, 화씨), IQ, 시험 점수
- 비율 척도:
- 범주 사이의 간격이 일정하고 절대적인 0값이 존재하는 척도입니다.
- 사칙연산이 모두 가능합니다.
- 예: 키, 몸무게, 나이, 소득, 길이
- 등간 척도:
모집단
통계적 연구대상이 되는 전체집합
- 모든 대한민국 국민
- 너튜브 회원전체
- A기업에서 생산한 전체 건전지의 수명




확률적 표본추출 방법
단순 무작위 표본추출: 일정한 규칙을 적용하여 모집단으로부터 표본을 기계적으로 추출하는 방법
- 컴퓨터로 추출
- 난수표를 활용(ex. 13,21,23,34,45,89,09, 12, 66, 77,...)
체계적 표본추출: 모집단의 대상으로 각각에 대해 번호를 부여하고, 일정 간격으로 표본을 추출하는 방법
- 선거 당일 출구에서 투표를 하고 나오는 유권자 순서대로 1, 5, 10, 15,... 번째 유권자를 대상으로 조사
비례 층화 표본추출: 모집단을 여러 개의 계층으로 구분한 후, 각 계층의 구성 비율에 따라 표본을 추출하는 방법
- 총원이 10,000명인 K대학교에서 1, 2, 3, 4학년의 비율이 '2:3:3:2'임
- 1,000명을 추출하고자 할 때, 각 학년을 구성하는 비율대로 학년별로 각각 200명, 300명, 300명, 200명씩 추출하여 표본을 구성
다단계 층화 표본추출: 비례 층화 표본추출에서 상위, 하위 표본 단위를 설정한 후, 설정한 값에 따라 다시 추출하는 방법
- 총원이 10,000명인 K대학교에서 1,000명을 추출하고자 할 때, 먼저 학부별로 구분 지은 후 다시 학과별 구성에 맞추어 표본을 추출하는 방법
군집 표본추출: 모집단의 구성이 내부 이질적인 동시에 외부 동질적으로 구성되어 있을 경우 모집단 전체를 조사하지 않고 몇 개의 군집을 표본으로 선택해서 조사하는 방법
- 서울시민을 대상으로 전기차 구매의사를 조사하고자 할 때 25개 구를 모두 조사하지 않고 표본으로 몇 개의 구를 선택하여 조사하는 방법
비확률적 표본추출 방법
편의 표본추출: 모집단의 구성이 내부 이질적인 동시에 외부 동질적으로 구성되어 있을 경우 모집단 전체를 조사하지 않고 몇 개의 군집을 표본으로 선택해서 조사하는 방법
- 연구나 조사를 수행함에 있어 편리하며 비용 또한 적게 든다는 장점이 있음. 하지만 모집단에 대한 대표성을 나타내기 힘들며, 실수나 오류가 많이 발생할 수 있음
판단 표본추출: 연구자나 조사자가 적절하다고 판단된 구성원들을 표본으로 선정하는 방법
- 편의 표본추출은 표본을 무작위로 선정하는 방법이지만, 판단 표본추출은 표본으로 선택할지 여부를 연구자나 조사자가 판단함
할당 표본추출: 모집단의 속성에 따라 일정한 기준을 정하여 집단별로 층화하는 것처럼 집단을 먼저 나누고, 각 집단에 할당된 표본의 수만큼 임의로 추출하는 방법
자발적 표본추출: 연구자나 조사자의 개입없이 임의적인 응답자들이 조사에 응하는 경우 표본으로 선정하는 방법
- 연구나 조사 대상에 대해 관심있는 사람들이 주로 연구나 조사에 참여하게 될 것이므로 결과가 왜곡될 가능성이 농후함
기술통계
통계란 여러가지 현상에 대해서 수리적으로 정리, 분석, 예측하는 작업
기술통계란 수집된 자료의 특성을 요약, 정리하는 것
gapminder 데이터 판다스 실습





도수분포표
수집한 각각의 데이터에 대한 빈도를 정리한 표

히스토그램은 측정치들을 계급으로 구분하고 각 계급에 포함되는 측정치의 개수(도수)를 표현한 것
- 각 계급 간의 상한과 하한이 서로 연결되기 때문에 히스토그램의 막대그래프는 서로 붙어 있는 형태로 표시함
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
df = pd.read_csv('gapminder.tsv', sep='\t')
plt.hist(df['lifeExp'], alpha = 0.3, bins=7, rwidth=1, color='red')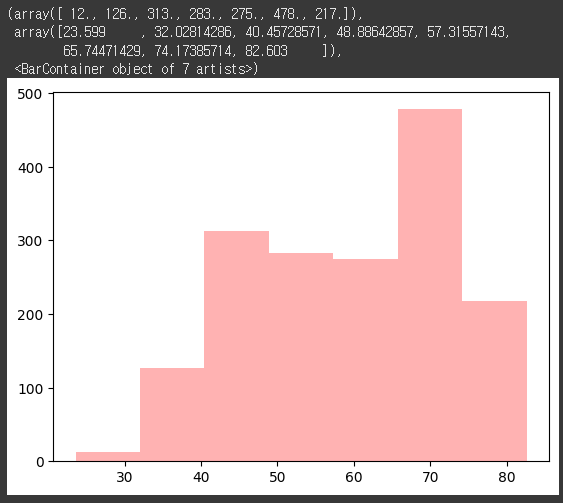
원그래프
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
df = pd.read_csv("gapminder.tsv", sep="\t")
df2 = df.groupby('continent')
# 원그래프
sizes = [624, 300, 396, 360, 24]
labels = [1, 2, 3, 4, 5]
colors = ['red', 'green', 'blue', 'yellow', 'purple']
plt.pie(sizes, labels = labels, colors = colors, autopct = '%.1f%%', shadow = False, startangle = 90 )
plt.axis('equal')
plt.show()
상자 수염 그림은 일반적으로 2개 이상의 집단의 자료를 서로 비교하는 데 사용
- 그림 자체에서 최댓값, 최솟값, 평균, 중앙값 등 여러 가지 정보를 제공하여 자료를 비교하는 데 유용함
import pandas as pd
import matplotlib
import seaborn as sns
df = pd.read_csv('gapminder.tsv', sep='\t')
sns.boxplot(x='continent', y='lifeExp', data=df)
기술통계량은 표본 데이터를 요약하고 설명하는 데 사용되는 측정값입니다. 즉, 표본 데이터의 특징을 파악하기 쉽게 수치화한 것입니다.
예를 들어, 학급 학생들의 키를 조사했다면, 그 키 데이터를 요약하는 기술통계량으로 평균 키, 가장 작은 키, 가장 큰 키 등을 계산할 수 있습니다.
기술통계량은 데이터 분석의 첫 단계에서 데이터의 전반적인 특징을 파악하는 데 유용하게 사용됩니다.
주요 기술통계량에는 다음과 같은 것들이 있습니다.
- 중심 경향: 데이터의 중심 위치를 나타내는 척도입니다. 평균, 중앙값, 최빈값 등이 이에 속합니다.
- 산포도: 데이터가 얼마나 퍼져 있는지를 나타내는 척도입니다. 범위, 분산, 표준 편차, 사분위수 범위 등이 이에 속합니다.
- 분포의 형태: 데이터의 분포 형태를 나타내는 척도입니다. 왜도, 첨도 등이 이에 속합니다.
기술통계량은 데이터 분석의 기초적인 도구이며, 데이터를 이해하고 해석하는 데 필수적인 역할을 합니다.
평균

평균의 특징
- 평균으로부터 관찰값과의 편차의 합은 0임
- 자료의 분포가 좌우대칭인 경우 평균과 중앙값은 동일함
- 대표값으로 가장 많이 사용됨
중앙값
중앙값은 관측된 자료의 편중과는 상관없이 최소값부터 최대값까지 나열했을 때 가운데 위치한 값입니다.

중앙값의 특징
- 자료에 극단적인 값이 있더라도 영향을 덜 받습니다.
- 평균과 달리, 자료의 분포에 따라 값이 크게 변하지 않습니다.
- 순서 척도 이상의 자료에서 사용할 수 있습니다.
pandas median() 함수 사용
최빈값
최빈값은 자료에서 가장 자주 나타나는 값입니다.
최빈값의 특징
- 계산이 쉽고 이해하기 쉽습니다.
- 극단적인 값의 영향을 받지 않습니다.
- 명목 척도 자료에도 사용할 수 있습니다. (예: 가장 많이 팔린 상품, 가장 선호하는 색깔 등)
- 자료에 따라 최빈값이 여러 개이거나 없을 수도 있습니다. (예: 모든 값이 한 번씩만 나타나는 경우)
pandas mode() 함수
모분산
모분산은 표본의 분포 특성을 잘 드러내지 못하는 평균의 단점을 해소하기 위하여 평균과 각 표본들이 얼마나 떨어져 있는지를 측정한 차이(편차)를 확인하는 것입니다.
다시 말해, 모분산은 데이터가 평균을 중심으로 얼마나 퍼져 있는지를 나타내는 척도입니다. 모분산이 크면 데이터가 평균에서 멀리 퍼져 있는 것이고, 모분산이 작으면 데이터가 평균에 가깝게 모여 있는 것입니다.

모분산을 구하는 방법
- 각 데이터 값에서 평균을 뺀 값을 제곱합니다. (편차의 제곱)
- 모든 편차의 제곱을 더합니다.
- 데이터 개수로 나눕니다.

모분산의 특징
- 모분산은 항상 0 이상의 값을 가집니다.
- 모분산의 단위는 원래 데이터 단위의 제곱입니다. (예: 원래 데이터가 cm 단위이면 모분산은 cm² 단위)
- 모분산은 극단적인 값에 민감합니다.
표본분산
표본분산은 모집단 전체 데이터를 사용하여 계산하는 모분산과 달리, 표본 데이터를 사용하여 모집단의 분산을 추정하는 것입니다.
모집단 전체 데이터를 구하기 어려운 경우가 많기 때문에, 현실적으로는 표본분산을 사용하여 모집단의 분산을 추정합니다.
표본분산을 구하는 방법
- 각 데이터 값에서 표본 평균을 뺀 값을 제곱합니다. (편차의 제곱)
- 모든 편차의 제곱을 더합니다.
- 데이터 개수 - 1 로 나눕니다.

모분산과의 차이점
표본분산은 모분산과 계산 방법이 거의 동일하지만, 마지막 단계에서 데이터 개수가 아닌 데이터 개수 - 1 로 나눕니다. 이는 표본 데이터만으로 모집단의 분산을 추정할 때 발생하는 편향을 보정하기 위한 것입니다.
자유도
표본분산을 계산할 때 데이터 개수 - 1을 자유도라고 부릅니다. 자유도는 통계학에서 데이터를 분석할 때 독립적으로 변할 수 있는 값들의 수를 의미합니다. 표본분산에서는 표본 평균이라는 제약 조건이 추가되기 때문에 자유도가 1 감소합니다.
표본표준편차

사분위수
사분위수는 데이터를 크기 순서대로 나열했을 때 4등분하는 지점을 의미합니다. 즉, 데이터를 4개의 동일한 부분으로 나누는 값들입니다.
사분위수는 Q1, Q2, Q3 이렇게 3개가 있습니다.
- Q1 (제1사분위수): 데이터의 25%가 Q1보다 작거나 같습니다.
- Q2 (제2사분위수): 데이터의 50%가 Q2보다 작거나 같습니다. Q2는 중앙값과 같습니다.
- Q3 (제3사분위수): 데이터의 75%가 Q3보다 작거나 같습니다.
사분위수를 구하는 방법
- 데이터를 크기 순서대로 정렬합니다.
- Q2 (중앙값)을 찾습니다.
- Q2를 기준으로 하위 50% 데이터에서 중앙값을 찾습니다. 이 값이 Q1입니다.
- Q2를 기준으로 상위 50% 데이터에서 중앙값을 찾습니다. 이 값이 Q3입니다.
사분위수의 활용
- 데이터의 분포 파악: 데이터가 어떻게 퍼져 있는지, 극단적인 값은 없는지 등을 파악할 수 있습니다.
- 이상치 탐지: Q1과 Q3을 이용하여 사분위 범위(IQR = Q3 - Q1)를 계산하고, 이를 이용하여 이상치를 탐지할 수 있습니다.
- 데이터 집합 비교: 여러 데이터 집합의 사분위수를 비교하여 데이터의 분포를 비교할 수 있습니다.
- 상자 그림: 사분위수를 이용하여 상자 그림을 그릴 수 있습니다. 상자 그림은 데이터의 분포를 시각적으로 보여주는 유용한 도구입니다.
사분위수 범위 (IQR)
사분위수 범위 (IQR)는 Q3 - Q1으로 계산됩니다. IQR은 데이터의 중간 50%가 포함되는 범위를 나타냅니다. IQR을 이용하여 이상치를 탐지할 수 있습니다. 일반적으로 Q1 - 1.5 * IQR 보다 작거나 Q3 + 1.5 * IQR 보다 큰 값을 이상치로 간주합니다.
기술통계 코드 표현
- df.mean(): 데이터프레임 df의 각 열에 대한 평균을 계산합니다. 숫자형 데이터가 있는 열에 대해서만 평균을 계산하고, 문자열이나 다른 데이터 타입의 열은 무시합니다.
- df.max(): 데이터프레임 df의 각 열에 대한 최댓값을 찾습니다. 숫자형 데이터뿐만 아니라 문자열 데이터의 경우에도 사전 순서에 따라 가장 마지막에 오는 값을 반환합니다.
- df.min(): 데이터프레임 df의 각 열에 대한 최솟값을 찾습니다. 숫자형 데이터뿐만 아니라 문자열 데이터의 경우에도 사전 순서에 따라 가장 먼저 오는 값을 반환합니다.
- df.median(): 데이터프레임 df의 각 열에 대한 중앙값을 계산합니다. 숫자형 데이터가 있는 열에 대해서만 중앙값을 계산합니다.
- df.var(): 데이터프레임 df의 각 열에 대한 분산을 계산합니다. 숫자형 데이터가 있는 열에 대해서만 분산을 계산합니다. 분산은 데이터가 평균으로부터 얼마나 퍼져 있는지를 나타내는 척도입니다.
- df.std(): 데이터프레임 df의 각 열에 대한 표준편차를 계산합니다. 숫자형 데이터가 있는 열에 대해서만 표준편차를 계산합니다. 표준편차는 분산의 제곱근으로, 데이터의 퍼짐 정도를 나타내는 척도입니다.
- df.describe(): 데이터프레임 df의 각 열에 대한 기술통계 요약을 보여줍니다. 숫자형 데이터가 있는 열에 대해서는 개수, 평균, 표준편차, 최솟값, 사분위수, 최댓값을 출력합니다. 범주형 데이터가 있는 열에 대해서는 개수, 고유값 개수, 최빈값, 최빈값의 빈도를 출력합니다.
import pandas as pd
# 데이터프레임 생성
data = {'age': [25, 30, 22, 28, 35, 27],
'city': ['서울', '부산', '서울', '대구', '서울', '부산']}
df = pd.DataFrame(data)
# 평균
print(df.mean()) # age 27.833333
# dtype: float64
# 최댓값
print(df.max()) # age 35
# city 서울
# dtype: object
# 최솟값
print(df.min()) # age 22
# city 대구
# dtype: object
# 중앙값
print(df.median()) # age 27.5
# dtype: float64
# 분산
print(df.var()) # age 20.966667
# dtype: float64
# 표준편차
print(df.std()) # age 4.578937
# dtype: float64
# 기술통계 요약
print(df.describe()) # age
# count 6.000000
# mean 27.833333
# std 4.578937
# min 22.000000
# 25% 25.250000
# 50% 27.500000
# 75% 29.750000
# max 35.000000
왜도
왜도는 자료의 분포가 좌우 대칭인지, 아니면 어느 한쪽으로 치우쳐 있는지를 나타내는 척도입니다.

첨도
첨도는 데이터 분포의 뾰족한 정도를 나타내는 척도입니다. 쉽게 말해, 데이터가 중심에 얼마나 집중되어 있는지, 혹은 꼬리가 얼마나 두꺼운지를 나타냅니다.

1. 스칼라 (Scalar)
- 크기만 가지는 양입니다.
- 예를 들어, 온도, 질량, 속력 등이 스칼라에 속합니다.
- 숫자 하나로 표현됩니다. (예: 20℃, 5kg, 100km/h)
2. 벡터 (Vector)
- 크기와 방향을 모두 가지는 양입니다.
- 예를 들어, 속도, 힘, 변위 등이 벡터에 속합니다.
- 일반적으로 화살표로 표현하며, 화살표의 길이는 크기를, 화살표의 방향은 방향을 나타냅니다.
- 숫자 여러 개를 순서대로 나열하여 표현합니다. (예: (3, 4)는 x축 방향으로 3, y축 방향으로 4만큼 이동하는 벡터)
3. 행렬 (Matrix)
- 숫자 또는 기호를 직사각형 형태로 배열한 것입니다.
- 행(row)과 열(column)로 구성됩니다.
- 예를 들어, 2x3 행렬은 2개의 행과 3개의 열로 이루어진 행렬입니다.
- 데이터를 표현하고 처리하는 데 유용하게 사용됩니다. (예: 이미지, 표, 연립방정식 등)
스칼라, 벡터, 행렬의 연산
- 스칼라: 덧셈, 뺄셈, 곱셈, 나눗셈 등의 사칙연산이 가능합니다.
- 벡터: 덧셈, 뺄셈, 스칼라 곱, 내적, 외적 등의 연산이 가능합니다.
- 행렬: 덧셈, 뺄셈, 스칼라 곱, 행렬 곱, 전치, 역행렬 등의 연산이 가능합니다.
'공부 > AI' 카테고리의 다른 글
| 컴퓨터 공학 (CSE) - Computational Thinking (0) | 2024.12.04 |
|---|---|
| 통계학 Statistics 공부 for AI - 2 (0) | 2024.12.01 |
| 파이썬 컨테이너 Container 튜플 tuple (0) | 2024.11.28 |
| 파이썬 컨테이너 Container 딕셔너리 dict (0) | 2024.11.25 |
| 파이썬 컨테이너 Container 리스트 list (0) | 2024.11.24 |